
FUSION-Model
Collection
5 items • Updated • 3
This is the checkpoint after Stage 1, Stage1.5 and Stage2 training of FUSION-LLaMA3.1-8B.
This repository contains the model described in the paper FUSION: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding.
Model Description
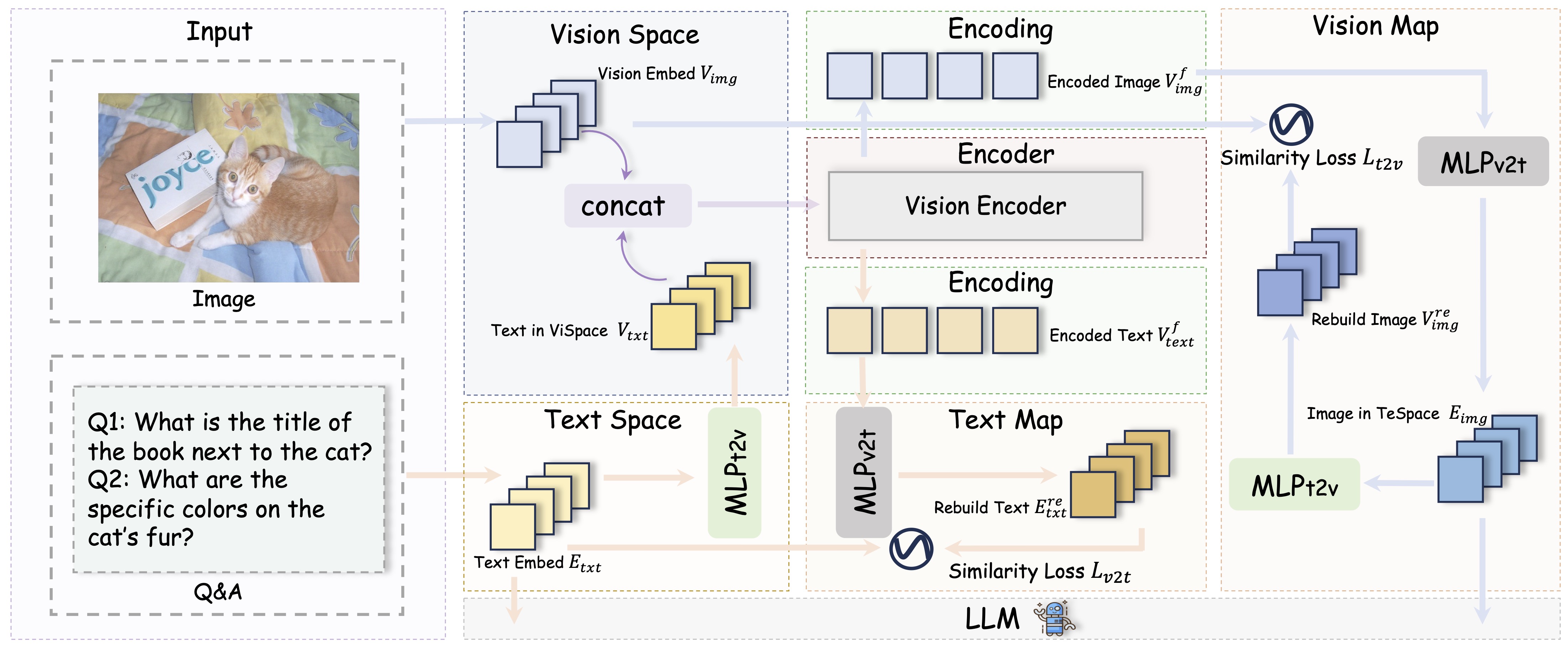
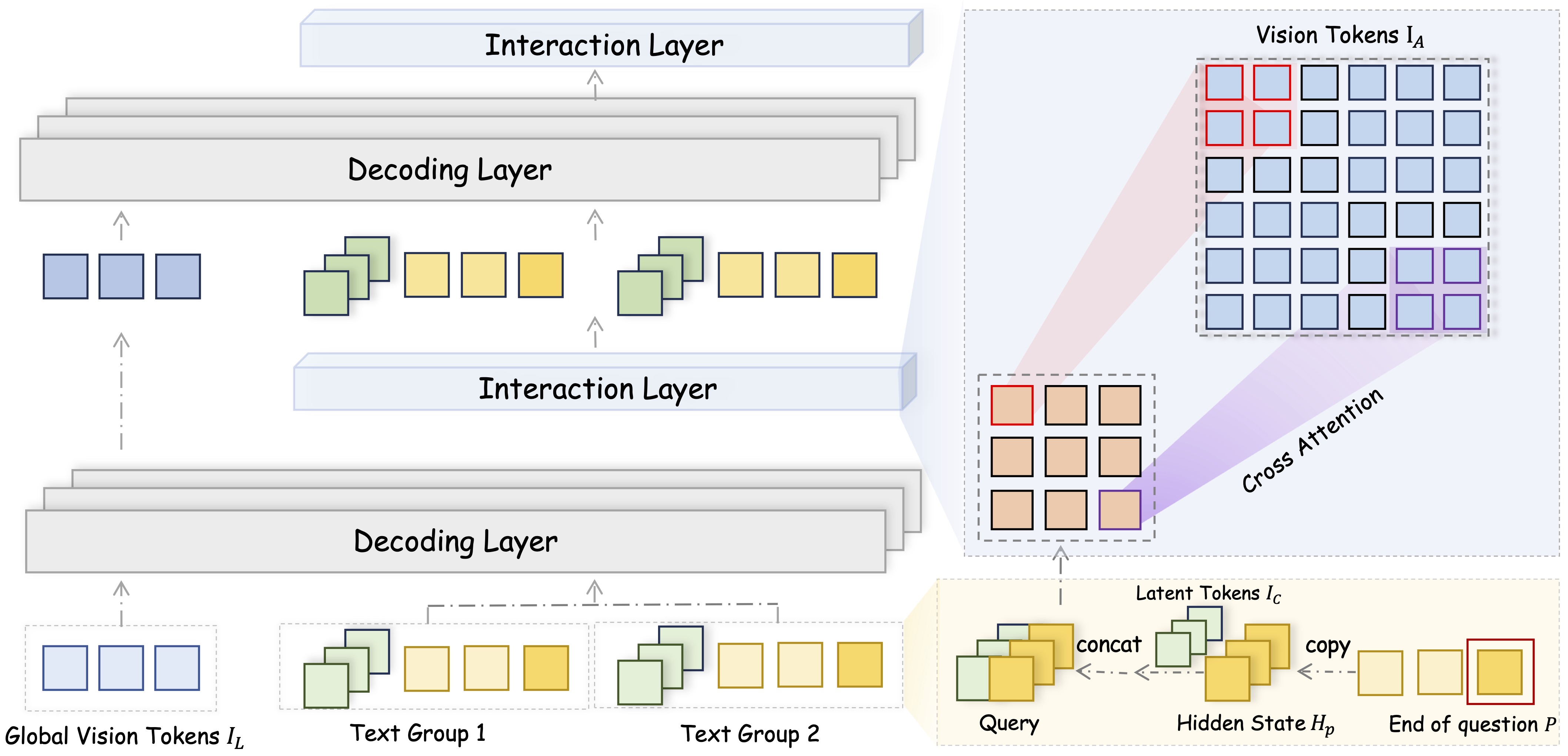
FUSION is a family of multimodal large language models that adopts a fully integrated vision-language architecture, enabling comprehensive and fine-grained cross-modal understanding. In contrast to prior approaches that primarily perform shallow or late-stage modality fusion during the LLM decoding phase, FUSION achieves deep, dynamic integration across the entire vision-language processing pipeline.
To enable this, FUSION utilizes Text-Guided Unified Vision Encoding, which incorporates textual context directly into the vision encoder. This design allows for pixel-level vision-language alignment and facilitates early-stage cross-modal interaction.
During decoding, FUSION employs Context-Aware Recursive Alignment Decoding strategy. This component dynamically aggregates and refines visual features based on the evolving textual context at each decoding step, allowing the model to capture question-level semantics with high precision.
To further enhance alignment and reduce the semantic gap between modalities, FUSION integrates Dual-Supervised Semantic Mapping Loss, which provides simultaneous supervision in both visual and textual embedding spaces. This dual-path guidance strengthens the consistency and semantic coherence of the fused representations.
Base Model
LLM: meta-llama/Llama-3.1-8B-Instruct
Vision Encoder: google/siglip-so400m-patch14-384
Training Strategies
FUSION is trained with a three-stage training framework, ensuring comprehensive alignment and integration between visual and linguistic modalities.
Training Data
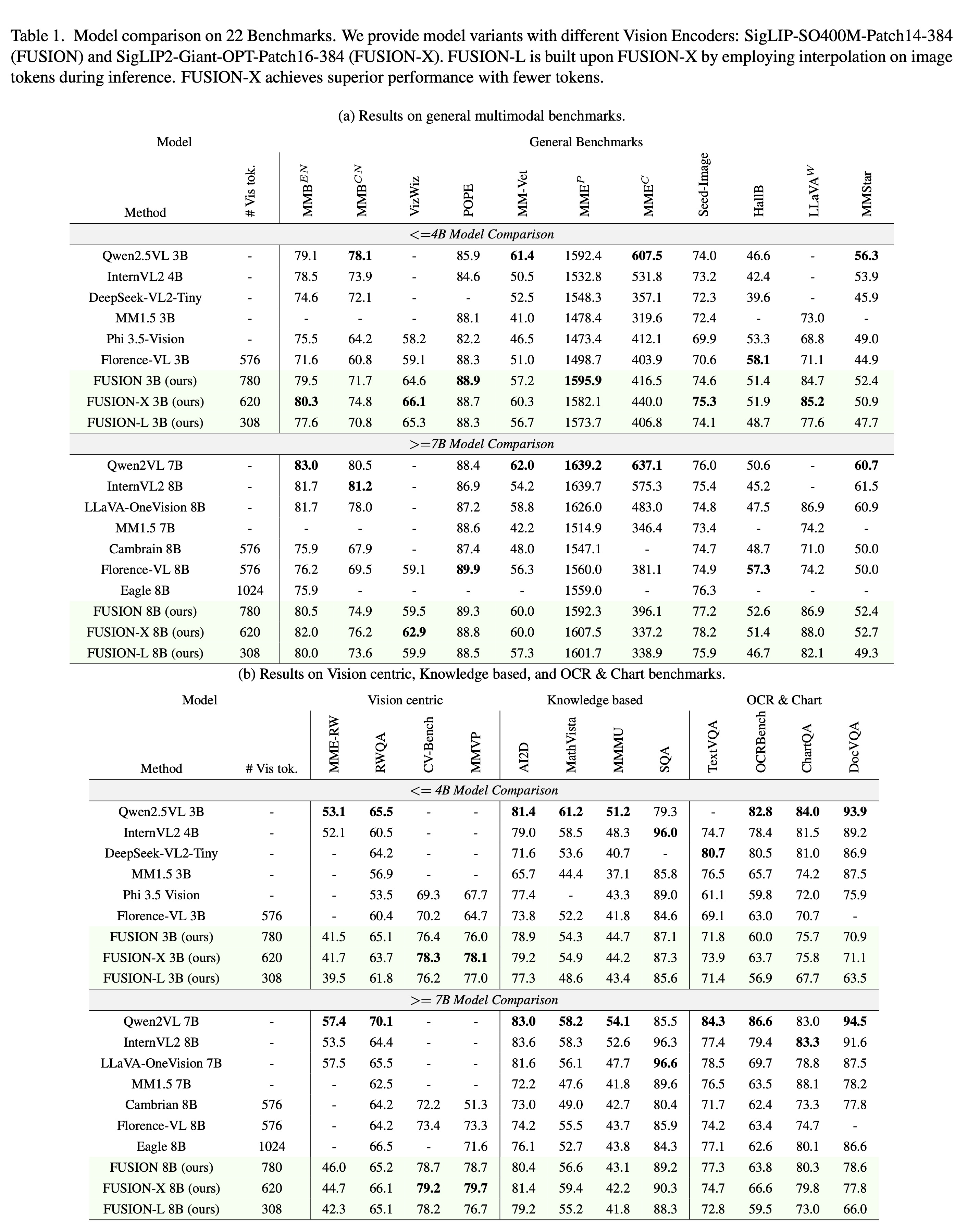
Where to send questions or comments about the model:
https://github.com/starriver030515/FUSION/issues
If you find FUSION useful for your research and applications, please cite using this BibTeX:
@misc{liu2025fusionfullyintegrationvisionlanguage,
title={FUSION: Fully Integration of Vision-Language Representations for Deep Cross-Modal Understanding},
author={Zheng Liu and Mengjie Liu and Jingzhou Chen and Jingwei Xu and Bin Cui and Conghui He and Wentao Zhang},
year={2025},
eprint={2504.09925},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2504.09925},
}
Base model
google/siglip-so400m-patch14-384